What are Edge Cases?
Autonomous vehicles are surely one of the greatest technological demonstrations ever seen on this planet. Deep learning, the unbelievably rich pattern-matching technique that has revolutionized artificial intelligence, gives AVs an ability akin to seeing the world around them. Combine this with LIDAR, radar, and the accumulated hours of the world’s most talented engineers, and modern autonomous vehicle prototypes have truly become technological tours de force.
So why aren’t AVs already revolutionizing transportation?
Because right now they are either too error prone, or too limited in scope to be commercially viable. By some estimates it will take decades for AVs to work reliably enough without drivers to become commercially viable. Though most AV developers realize the real bottleneck isn’t the amount of time they need to develop better AVs, but how quickly they can expose their AVs to enough edge cases.
What is an edge case?
Put simply, edge cases are all the things that can go wrong in the real world that you never expected. And as any human driver knows, the roads are full of them. Consider a person emerging from a manhole without any of the cones or cordons typical of a construction zone. As a human driver, you know how to recognize another human in a huge number of configurations. Even if you had never driven by an open manhole you know it’s something to be avoided, as are any humans that might pop out of it. Humans have common sense that AVs, as pattern matchers, don’t have. So, since an AV has never matched the pattern of a human gingerly poking his head out of an unmarked open manhole, it won’t recognize that situation until it’s too late.
People emerging from un-cordoned manholes, El Paso TX. AV-level computer vision doesn’t recognize the human until seconds after the human driver does, and never even sees the open manhole at all. Video credit, BBC
How Edge Cases Data is collected?
Edge cases make up the vast majority of the risk on the road, but they are individually unlikely, which makes them hard to catalog. The most prominent AV developers have strategized that they will win the AV race by collecting the most data, edge cases and otherwise, by driving the most miles. On the surface, this seems like a good idea – it allows you to collect the real data your sensors will see during millions of miles of driving, and then repeatedly test your vehicle against that data as you improve its decision making policies.
The problem with this strategy is that most of the data collected end up being hundreds of terabytes of extremely uneventful driving. At one level, AV developers want to collect boring data, because they obviously don’t want to be getting into too many close calls or accidents. There’s an inherent conflict therefore between doing everything you can to make sure your vehicles don’t encounter a fatal situation and getting the data you need to make sure they could handle one. This conflict is compounded by the fact that fatal situations under any circumstances are extremely rare. Informed estimates show that to accumulate enough rare incidents to truly test their vehicle, AV developers would actually have to drive billions of miles [Kalra and Paddock, “Driving to Safety”, 2016]. Under current development procedures that would mean hundreds of years before AVs become commercially viable.
How Edge Case Data is Collected by Modern Approach
Clearly, we need modern approach. We believe the solution is to expose AVs to all the edge cases that everyone generates and observes. To actually collect this data from cameras mounted on cars would not be very efficient; again you’d get mostly boring data, you’d need to instrument hundreds of millions of cars worldwide to even get close to that billion miles figure, and you’d have to be very sure about your sensor configuration. But there’s another, much more efficient way to do it: assemble the evidence of what has caused accidents and near misses (both by human-driven vehicles, and AV/ADAS-enabled vehicles), and reconstruct those conditions in simulation with a combination of real and synthesized data. Also Read
Importance of dRISK Edge Cases in Autonomous Vehicles
This is where dRISK comes in. Over the last few years, we’ve assembled huge amounts of fatal accident reports, a ream of the non-fatal accident reports, and millions of examples of the tight, tricky interactions that occur between cars and other road users that AVs have a lot of trouble with right now, but which occur every moment in complex cities like London. These data come in all different forms, from raw text to video, so we need a little AI to codify them (natural language processing and computer vision). But now that we have them all in one place, we have substantially all the edge cases that autonomous vehicles need to be exposed to.
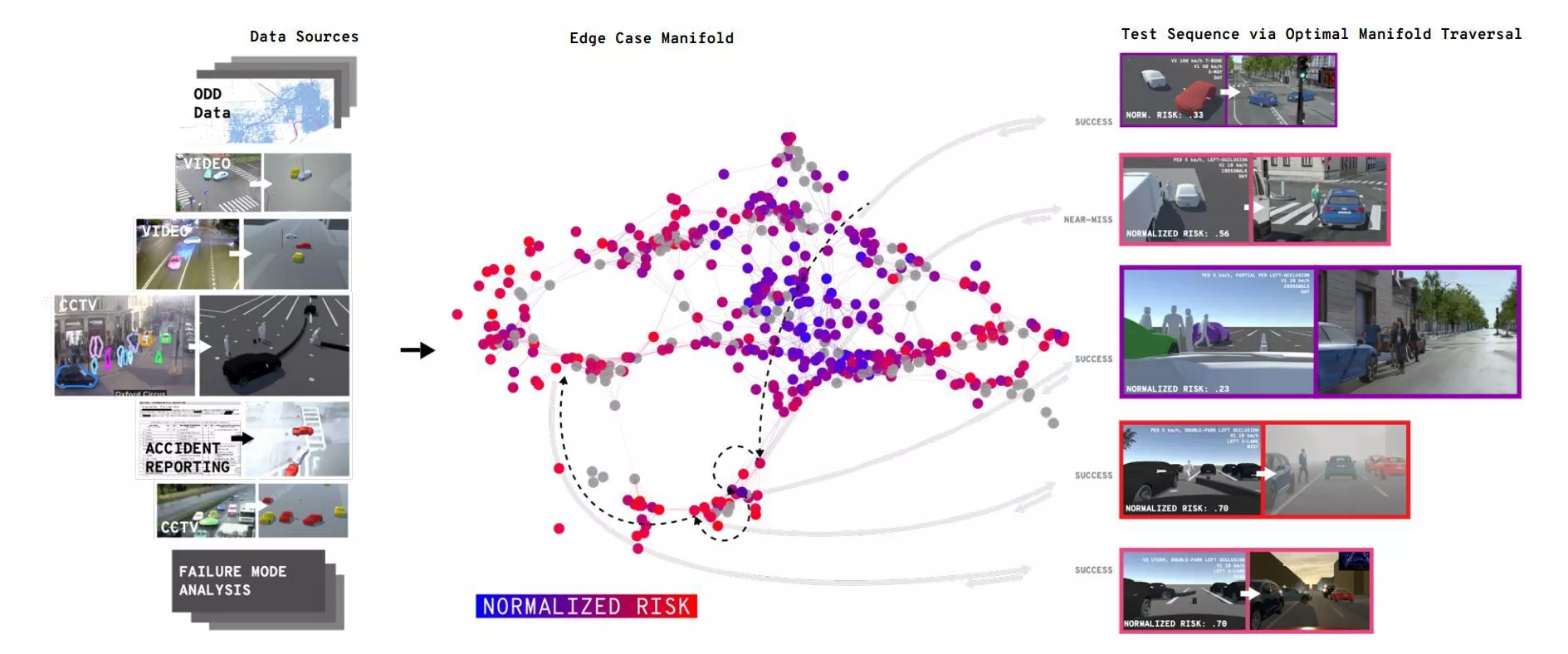
Illustration of dRISK method of drawing an optimal AV test sequence from a comprehensive taxonomy of edge cases.